Introduction
A lot goes on in the background every time you load up your favorite Netflix movie or series.
Engineers spread across Chaos Engineering, Performance Engineering and Site Reliability Engineering (SRE) are working non-stop to ensure the magic keeps happening.
📊 Here are some performance statistics for Netflix
When it was alone on top of the streaming world in 2016…
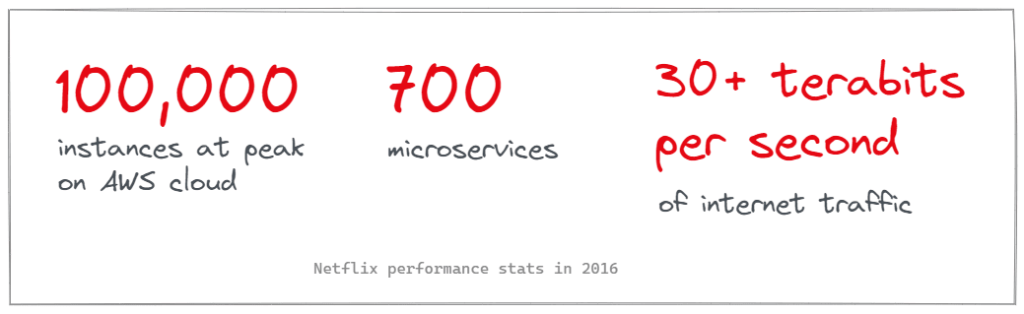
For context, the average HD video connection is 8mbps, so 30+ terabits/second means there were 3,750,000+ connections at high-definition video bitrate at any given time.
In 2022, this number must be significantly higher, but I don’t have access to their current numbers.
SREs played an essential role in making sure all of this performance ticked over smoothly.
🔱 How SRE fits into the Netflix culture
Team formation
The SRE team at Netflix is known as CORE (Cloud Operations Reliability Engineering). It belongs to a larger group known as Operations Engineering.
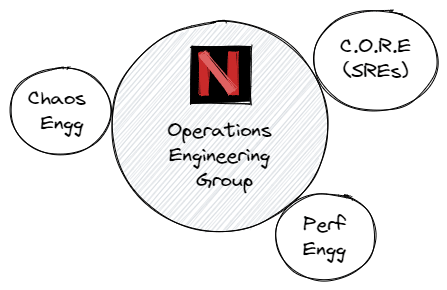
SREs work alongside specialist roles interrelated with SRE work, such as Performance Engineers and Chaos Engineers.
What is Netflix’s SRE culture like?
The culture at Netflix is freedom and responsibility — both are important to effective SRE work.
CEO Reed Hasting’s radical candor approach (now popularised by Kim Scott) has had an impact on this contradicting desire for freedom and responsibility.
The premise of radical candor is “be critical because you care about the other person“. This may make it easier for SREs to call out poor production decisions.
This would make it easier for SREs to tell their counterpart engineers when they are not following a more suitable path for solving a problem. Without looking like a jerk.
Developers must follow the “you build it, you run it” model. SREs act as consultants for developers in supporting them achieve the “you run it” part of the equation.
Of course, SREs will also act as the last line of defense when issues affect production.
For example, a testing service goes down, which will affect the ability to push code to production. SREs may join to resolve this issue by following incident response protocols.
Most of the time, Netflix’s SREs work on solving problems that don’t have a straightforward fix. In such instances, RTFM may not work and a willingness to experiment and seek novel solutions may help.
Fixes can take minutes, hours, days, weeks, or months — there is no fixed time to solve — and can be larger projects that other teams don’t have time for.
There is a lot of reading source code & documentation, sourcing experiment ideas, running experiments, and then measuring the outcomes
It can be done in solo missions or as a temporary problem-specific team.
🧰 How Netflix SREs support production tooling
Tooling ethos
Operations engineers at Netflix have spent years developing “paved paths”. These paths are designed to help developers leverage advanced tooling without reinventing the wheel.
Examples of what paths cover include: service discovery, application RPC calls and circuit breakers.
These paved paths are not prescriptive or enforced. Developers are allowed – even empowered – to deviate if they want to create a better path for their service.
SREs are of course there to help developers work out a better path’s design. A good idea to use their services because path deviators are still subject to attacks by the Simian army.
Simian Army is Netflix’s suite of chaos engineering tools that test out a functional system for its resilience when it’s attacked by an internal source.
It’s all useful as Netflix practices extreme DevOps — you build it, you run it — engineers do the full job of developing software, deploying pipeline and running code in production.
SREs codify best practices from past deployments to make sure production is optimal.
Tooling examples
Netflix is best known to SRE world for its Chaos Monkey tool in Chaos Engineering. But wait, there’s more!
Netflix’s SREs also work extensively with the following tools:
Below is an example of an SRE codified tool, a pre-production checklist — Is your service production ready?

Netflix SRE capability highlights
🔥 Incident Response
Netflix engineering’s #1 business metric is SPS – Starts Per Second — the number of people successfully hitting the play button.
Incident response practices are designed to ensure the highest possible % for this SPS metric.
Here are some of the practices that Netflix has affirmed in its incident response capability:
🏎️ Support performance engineers
For Netflix operations, it’s not only about uptime but also about having the right level of performance for solid playback.
There is a need for consistently good service performance rather than one-off wins — users should have acceptably low TTI and TTR.
Here’s what these two terms mean:
- TTI (time-to-interactive) – user can interact with app contents even if not everything is fully loaded or rendered
- TTR (time-to-render) – everything above the fold is rendered
SREs support performance engineers with activities like:
👾 Run Chaos Engineering at scale
Netflix is famous for its extensive use of chaos engineering to ensure all of the above metrics like SPS, TTI and TTR are going in the right direction.
What is chaos engineering?
Experimenting on a distributed system in order to build confidence in the system’s ability to withstand turbulent conditions in production — Nora Jones, ex-Senior Chaos Engineer, Netflix
Chaos engineering is a capability heavily based on Netflix’s work from 2008 through the early 2010s. It builds on the value of common tests like unit testing and integration testing.
Chaos work takes it up a notch from these older methods by adding failure or latency on calls between services.
Why do this? Because it helps uncover and resolve issues typically found when services call on another like network latency, congestion and logical or scaling failure
Adding Chaos to Netflix engineering has led to a culture shift from “What happens if this fails” to “What happens when this fails”.
How chaos engineering can be done
Parting remarks
Netflix SREs goes through all of these amazing fetes to make sure that you can easily binge-watch your fave show this weekend!

- #34 From Cloud to Concrete: Should You Return to On-Prem? – March 26, 2024
- #33 Inside Google’s Data Center Design – March 19, 2024
- #32 Clarifying Platform Engineering’s Role (with Ajay Chankramath) – March 14, 2024