In this article, you will learn the following:
- Why developers make excellent potential hires for new SREs
- How the work will be different for the developer once they become an SRE
- How developers can acquaint with SRE practices before applying for roles
- How apprenticeship programs can improve outcomes for budding SREs
- Onboarding tips for a smooth transition from developer → SRE
Introduction
Hiring in the Site Reliability Engineering (SRE) space is notoriously difficult. So it makes sense to figure out how to expand the hiring pool beyond existing SREs.
One way to increase the hiring pool is to recruit developers (also known as SWEs) and gradually advance them into SRE work.
We will exclusively explore the aforementioned method in this article.
Why are SREs so hard to hire despite the tech downturn?
The difficulty in hiring SREs has continued despite the ongoing tech downturn that has been in play since mid-2022.
It’s an interesting dichotomy.
While some of the larger tech companies are offloading some SRE positions, other companies are struggling to source the right kind of reliability talent.
The reasoning behind this could be that many laid-off SREs seek like-for-like opportunities. For example, an ex-FAANG SRE may want similar pay and benefits (and possibly hiring brand cachet) as before.
Most smaller companies would not be able to come close to the perks and pay that were being offered at the “top end of town” in tech.
What is a hiring manager in a less well-known or less “generous” company to do?
In the middle of every difficulty lies opportunity.
Hiring developers overcomes an SRE hiring issue
A common pattern for filling SRE talent gaps in organizations — especially non-tech companies — is to turn existing sysadmins into SREs.
The challenge that comes with this is that SRE work may involve digging through code or at least understanding how it works. Not all, but many admins don’t have this experience or interest.
Having mastery of at least one programming language is advantageous.
An SRE should be able to configure open-source tools in their codebase and also make custom tools. This gives a natural advantage to people who work with code all the time: developers.
Shashank Katlaparthi, a Site Reliability Engineer at Redhat, shared his thoughts regarding the coding prowess of SREs:
In my current role, we SREs not only code our product/application, we set up a CI/CD process and automate the scaling/provisioning/error-handling of the Infrastructure to test our product code. To summarize, we not only code for the application, but we code the Infrastructure itself. And no, we are not using tools as-is; we are building new ones.
Adjacent roles also find the need for developer backgrounds useful.
Performance Engineering is a role and skillset that has a lot of crosslinking with SRE as a practice. It’s interesting to note that performance engineering managers also find it useful to work with people who have software development expertise:
In my current role, I interview candidates applying for Performance Engineer (PE) or Senior Performance Engineer roles and find most don’t have any or enough software background to be effective on my team. In the end, the team I currently lead is mostly software developers, who happen to work on performance-related things. — Anonymous PE Manager
Hiring a developer with several years of experience should be an advantage.
Okay, but…
Why would developers switch to SRE?
Here are a few reasons why developers may consider the move:
- salaries are 10-25% higher — compared to early-career developers — but this should not be the key reason
- job security may be higher due to the continued tightness in the SRE hiring market compared to the wider developer hiring market
- if it better suits their mental model for a career — they are self-directed, prefer unique challenges, and thrive in ambiguous situations
- they have an actual interest in the whole system (networks, infrastructure, etc.) — system-wide thinkers might begin to find the small picture codework stifling
One other aspect is that there will always be demand for SREs.
Companies will be compelled to hire SREs as they scale up or increase the complexity of their infrastructure and software architecture.
If they aim to scale up linearly by adding more operations engineers, they will need an extremely large volume of such people.
SRE acts like a fulcrum where one SRE can automate to the level that would normally call for several non-software-driven operations people.
The prospect for SREs seems good, right?
There is an elephant in the room that I want to address.
SRE has had a rough start as a practice in many organizations with more traditional backgrounds and without robust investment in operations and infrastructure.
If you go on the r/SRE subreddit or Slack chats, you may have noticed that many SREs are asking how to switch over to developer work.
This might have you doubting the possibility of turning developers into SREs.
I initially thought, “They must prefer coding or working on product”, but I was wrong.
Many of these posts by SREs had a common thread: they felt the grass would be greener on the other side i.e. on feature teams. I noticed a common thread among these people. They had SRE job titles, but more than 75-90% of their time was consumed by firefighting work.
Many of these folks were solely focused on handling tickets and infra-provisioning.
These tasks are something a junior SRE might do to understand the system and issues, but they should not form the ongoing career progression of an SRE.
Site Reliability Engineering work is so much more than that.
In plain terms, you’ll need to be proactively working on problems rather than firefighting, have a broader view of systems, and more, which is kinda exciting.
Developers may still find it hard to switch to SRE
Developers have an advantage as they have coding ability that’s useful to SRE work, but there’s a lot more to how the role functions.
Developers moving into SRE roles will need to:
- accept that they might not code anything for a while (even though its originators at Google coined SRE to be a software engineering approach to operations)
- take a much broader system view than a product team or engineer that typically focuses on a single or at most a handful of microservices
- start thinking in a proactive manner — SRE is a movement to do away with reactive operations; as you progress, you will need to find problems yourself
- work under pressure when a critical part of the system is malfunctioning, and you’re involved in the incident response
Here are some more reasons why it’s difficult to get that mindset shift into SRE as a developer:
An SRE’s scope of work is W-I-D-E
Site Reliability Engineers often find themselves doing the following:
- Working to drive or support org-wide acceptance of a change
- Negotiating trade-offs within systems with product and other teams
- Setting boundaries for scalability
- Bringing Sec (supporting security engineering concepts) into DevOps to make it DevSecOps
An SRE’s toolbox is H-U-G-E
A Site Reliability Engineer can expect to work with a combination of the following:
- Linux and all its componentry
- Software languages: Ruby, Python, C++, Java
- Databases: MySQL, Cassandra, NoSQL
- JavaScript extensions: Node JS, React, TypeScript
- Cloud platforms and their 100+ sub-services: AWS, Azure, GCP, etc.
- Distributed systems: load balancing, data replication
- Infrastructure tooling: Terraform, Cloud Formation, Ansible, Bash scripting
- Container tooling: Kubernetes, Docker, Meso
- Observability tooling, incident management systems
- Computer hardware – understand different CPU types, memory, storage, etc.
- Networking e.g. TCP/IP and kernel skills are highly advantageous…
40–50% are [SRE] candidates who were very close to the Google Software Engineering qualifications (i.e., 85–99% of the skill set required), and who, in addition, had a set of technical skills that is useful to SRE but is rare for most software engineers. By far, UNIX system internals and networking (Layer 1 to Layer 3) expertise are the two most common types of alternate technical skills we seek. — Stephen Thorne, Staff SRE @ Google
As stated earlier, an SRE ideally needs development and systems-oriented skills – a *Pi-shaped* skill set, so to speak.
For this type of skill set, an SRE has to be proficient in both trades. Two areas of deep expertise with a broader understanding of other areas to form the pi shape.
Not just one or the other, which is the hallmark of a T-shaped skill set.
Difference between working styles of SREs and developers
Site Reliability Engineering is still a relatively rare role in the broader software community.
However, there’s little denying that the approach of Site Reliability Engineering is the future of software operations.
Here are some things that make SREs a unique breed in software work:
SREs look at the broader picture
Ask any developer what they’re working on, and you’ll see a tiny sliver of the whole codebase. That makes sense for the kind of work that is coding up a feature or update.
Systems work, on the other hand, needs a holistic view of significant complexity in order to make sure the whole unit works harmoniously.
SREs thrive in ambiguity
Because they have a scope spanning the entirety of a software system, SREs can end up working on various types of problems.
They may solve challenging problems which could take days, weeks, or months to resolve.
The old adage of “how long is a piece of string?” can apply to SREs estimating a fix for issues.
Some problems may be well-defined, like spooling up infrastructure based on known demand.
Other problems may be more abstract, like working out how to cost-effectively autoscale a service that has inconsistent usage patterns and needs high performance.
SREs work beyond constraints like Scrum
Most developers work within agile frameworks like Scrum or XP. SREs may also use these frameworks when planning software build work.
That essentially timeboxes their efforts, which is fine but…
That might work for estimable problems but does not always work for production-level work.
Can an SRE stop working on a problem because it does not fit into the mold of a sprint? That could spell disaster for production software. Daniel Wilhite answers the question of “Can scrum be used effectively by SRE teams?” very well.
SREs don’t stay in their lane
You’d expect SREs to get used to developers throwing the code over the wall, but no. Many are ex-developers, so they will spend much of their time coding up solutions for infrastructure and software performance.
Sometimes, they may participate in feature teams for job rotation. This helps them get a better understanding of their developer counterparts’ priorities.
SREs don’t have a monolith job description
SREs come in many shapes and sizes. In smaller companies, a single SRE may be the one-stop shop for all site reliability matters. As a company grows, SRE roles may get divided into specialized work.
For example, one SRE may focus on supporting platforms like Kubernetes.
Another SRE may spend most of their time supporting developers in taking up DevSecOps.
Yet another may have general SRE responsibilities like being an incident commander.
Comparison with software developers
Both roles are chalk and cheese, so it’s worth considering key differences in how SREs work compared to software developers.
Chances are they will need to collaborate closely to make sure the software works well in production.
I took inspiration from a Google recruiter’s interview with an SRE, Ciara Kamahele (link here).
The key differences I uncovered are in table form below:
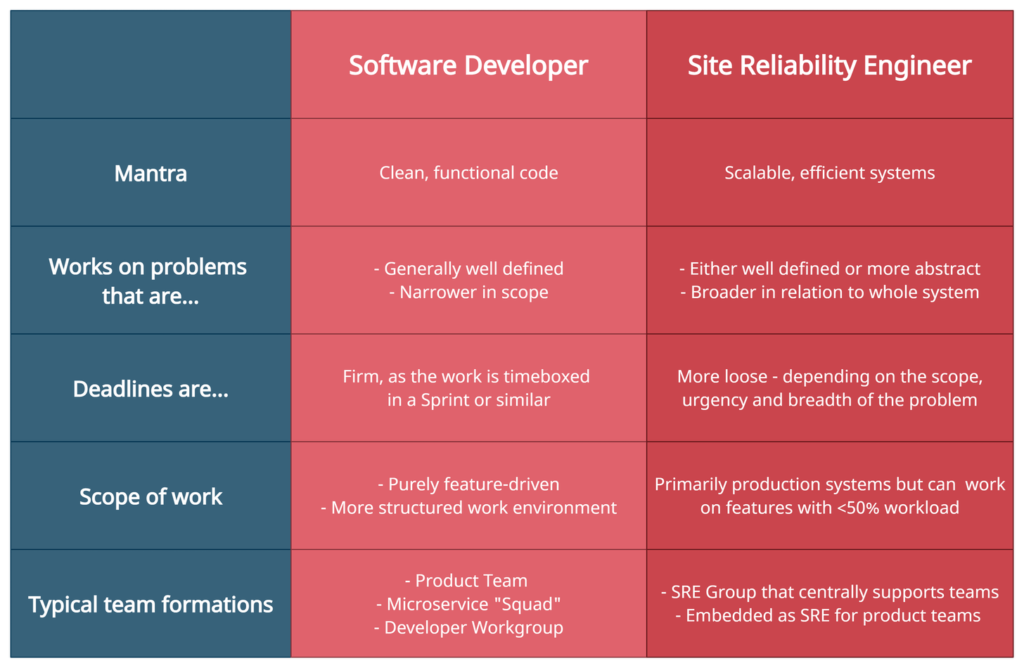
Pre-game plan for developers aiming for SRE jobs
Here’s a quick rundown of the steps a developer could take for a smooth transition to SRE work:
- Learn a system-oriented language e.g. Go, Rust
- Engage deeper with current SREs on LinkedIn, Reddit, Quora, and real-life events
- Subscribe to sreweekly.com and stay aware of what’s new in the SRE world
- Follow and contribute to cloud-native projects on GitHub and other places
- Interview for entry-level SRE roles i.e. become an apprentice (more on this below)
- Put together and break systems in sandboxes e.g. Chaos engineering
- Enhance uptake of skills by learning to learn well (like outlined here)
- Get acquainted with Google’s SRE (priorities) hierarchy, which I’ve broken down here
- Access free Coursera courses related to systems engineering, like Linux for Developers by the Linux Foundation and Introduction to Networking and Storage by IBM Skills Network
Helping developers safely enter SRE work
Avoid places with a sink-or-swim mentality
Sylvia Fronczak, a Senior Developer at Shopify, made a good point:
“Avoiding a sink or swim approach is important if you value inclusivity. Sink or swim breeds stress, frustration, attrition, and imposter syndrome.”
These sink-or-swim results are all the things we don’t want our new SREs to develop. It happening may highlight a larger structural problem in how the SRE team itself handles the work.
Google’s 2016 Site Reliability Engineering book named this particular issue “trial by fire”.
Here’s a quote from that book to highlight the issue:
This “trial by fire” method of orienting one’s newbies is often born out of a team’s current environment. Ops-driven, reactive SRE teams “train” their newest members by making them…well, react! Over and over again… the trial-by-fire approach also presumes that many or most aspects of a team can be taught strictly by doing, rather than by reasoning. If the set of work one encounters in a ticket queue will adequately provide training for said job, then this is not an SRE position. (source)
Become an apprentice
Google’s SRE book also has a particularly strong stance on apprenticeship.
Essentially, newly minted SREs should not be doing operations work all the time, but also see what supervisors and senior SREs are doing.
Newly transitioning SREs will look up to the rest of the team, especially senior people, to show them what a typical day should look like over time.
Henri Devieux, SRE at Dropbox, recommends the following for SRE apprentices:
“It’s important to create a focused plan for what you need to learn. The fundamentals will always be more important to nail down than any one awesome new piece of software. (editor’s note: including ChatGPT) Stay focused.”
One of New Relic’s SREs, Yonathan Schultz, has broken down his day in the life of an SRE to give a picture of a “typical day” of an experienced SRE.
But of course, there is no typical day for SREs.
New challenges emerge daily, and SREs do many complex activities that may seem alien to an apprentice.
Henri outlined that his day as an SRE could be comprised of a myriad of work like:
- Debugging systems over days or weeks
- Writing software for infrastructure
- Contribute to architecture discussions
- Periodic on-call rotations
To avoid causing cognitive overload, I suggest an onboarding program that eases apprentice SREs into increasingly complex work patterns.
Google’s Site Reliability Engineering book has a brilliant progression framework for onboarding SREs.
A formal apprenticeship program may be useful for SRE teams that can get VP support for it.
Tammy Bryant Butow created an SRE apprenticeship program when she first started working as an SRE manager at Dropbox.
This was a direct response to the difficulty she experienced hiring SREs. Here are the trigger events supporting the program:
- it was difficult to poach talent from other organizations — many existing SREs were satisfied with the work they were doing
- hiring through the traditional CompSci route at universities was leading to very homogenous SRE teams — they wanted to increase diversity by merit to counter this
Her apprenticeship program was in a 6-month format.
People from software engineering and technical manager backgrounds had 1:1 mentoring from an experienced SRE.
They could contribute through architecture ideas, sit in on postmortem meetings and ask questions about various aspects of the system.
Concepts were explained from grassroots all the way down to how to pronounce terms like NGINX. Tammy ensured that the curse of knowledge — “this should be obvious” — did not affect her mentees’ learning.
End results were:
- talent gaps were filled for SRE teams
- several mentoring engineers received promotions because their work was visible in a proper engineer development program and
- increased team diversity as the apprenticeship format made it easier for people from non-traditional backgrounds to participate, especially women of color
The full rundown of Tammy’s experience with her SRE apprenticeship program can be heard here
One final point: Tammy’s apprenticeship program at Dropbox did not guarantee a job at the end of it, but the pass rate was high.
Once your apprentices are ready to start a fully-fledged role, consider your onboarding work.
How to onboard newly minted SREs effectively
Your aim is to minimize time-to-productivity for your newly hired SRE.
Some prickly issues will come in the way. I picked up several tips from a post written by Gergely Orosz on ways more senior engineers get stuck when they take on a new role.
I’ve noticed that these issues affect new SREs too:
- Unclear role
- Going too broad in the role, too soon
- No clear deliverables in the first few months
- Poor clarity on how the organization works
- Not building empathy with the rest of the team
- No clarity on who they report to
Here are some concrete onboarding tips for SREs
I will aim to help you solve some of these prickly issues:
- Give their role crystal clarity to help drive more intentional actions
- Focus on mastery of a specific aspect of SRE e.g. working with observability instrumentation
- Create work with early wins, which will support ongoing progress
- Acquaint them with the whos and ways of the organization
- Bring them into team situations where they learn more about each person at a deeper level
- Make the reporting structure and performance expectations clear early on
- Have a balance of “thinking” work and “doing” work and not one or the other
Luca Rossi’s “small part of the puzzle” onboarding technique
I recently read an engineer onboarding post by Luca Rossi, who is an Italian developer influencer.
One of his recommendations was to break the work down into small pieces of a bigger puzzle and give them to the new hire for quick wins.
This made me think about the SRE context. Here are my thoughts:
- Get the new junior SRE productive from week 1 – give them an achievable task with an end result that can be achieved in a 10-15 hour block
- Examples of short, achievable tasks can include coding part of an existing story or completing an incident review with the incident commander
- Why do this? On their first week, the junior SRE will spend a lot of mental bandwidth acquainting with their socio-cultural environment and will want to feel like they can contribute (aka fit in)
You could potentially start junior SREs on a high process orientation i.e. Do this, then review this, etc. But as they progress, you need to let them work outside the boundaries of the “process”.
Google’s SRE book considers process orientation an antipattern.
In my experience, initially having a predetermined path for the work in the form of processes can alleviate a lot of ambiguity and stress.
The idea is to give training wheels and slowly take them off as the new SRE gets more confident.
Then it’s time to encourage tinkering, using statistical methods and scientific processes to solve ambiguous, complex problems.
Evolving the workload as new hires become more effective
- Give increasing levels of autonomy as they progress
- Avoid developing monolithic roles over time — evolve the work with a variety of responsibility
- Give them the choice to code their own solution or middleware it
- On-call or incident response should not become the primary responsibility (many SREs quit the industry because they never get past the reactive “dumpster fires”)
Final emphasis: at no point should SREs become the main destination for resolving operations tickets or taking the entire on-call load.
That turns them into operations in the traditional sense of responding to tickets as issues arise. Your SRE team will NOT benefit from their developer skills if they’re too busy putting out fires.
Developers will make effective SREs as long as you let them solve operations issues as software engineering problems.
Related work
I have been working on something exciting in the background for a while now. It’s not yet ready but I would like to have conversations with SRE managers to refine the approach.
It will be a software-based tool but oriented to the human side of SRE rather than the technology side. So nothing like an observability dashboard or incident triage tool.
Using it, SRE managers can map out the team’s work as it stands. They can then use it for 3 purposes:
- assign work to individual contributors across the full SRE spectrum (prevent gaps in capability)
- develop better individual contributors through feedback and learning loops (performance management)
- map out the team’s evolution across various aspects of SRE as priorities evolve (change management)
#1 and #2 will naturally help with integrating new hires and evolving their work over time.
If you are an SRE manager or know one who would be interested, reach out via LinkedIn or email ash [at] srepath [dot] com.

- #34 From Cloud to Concrete: Should You Return to On-Prem? – March 26, 2024
- #33 Inside Google’s Data Center Design – March 19, 2024
- #32 Clarifying Platform Engineering’s Role (with Ajay Chankramath) – March 14, 2024