Google’s book on SRE, Site Reliability Engineering (2016), has captured wide acclaim in the software operations world.
One of the most discussed aspects in SRE circles about the book is its SRE hierarchy. The hierarchy has merit, but it’s also flawed in a way that would prevent you from educating people about SRE.
I’ll get into this flaw later in the article.
First, let’s see this hierarchy. Looks more like a pyramid, right?
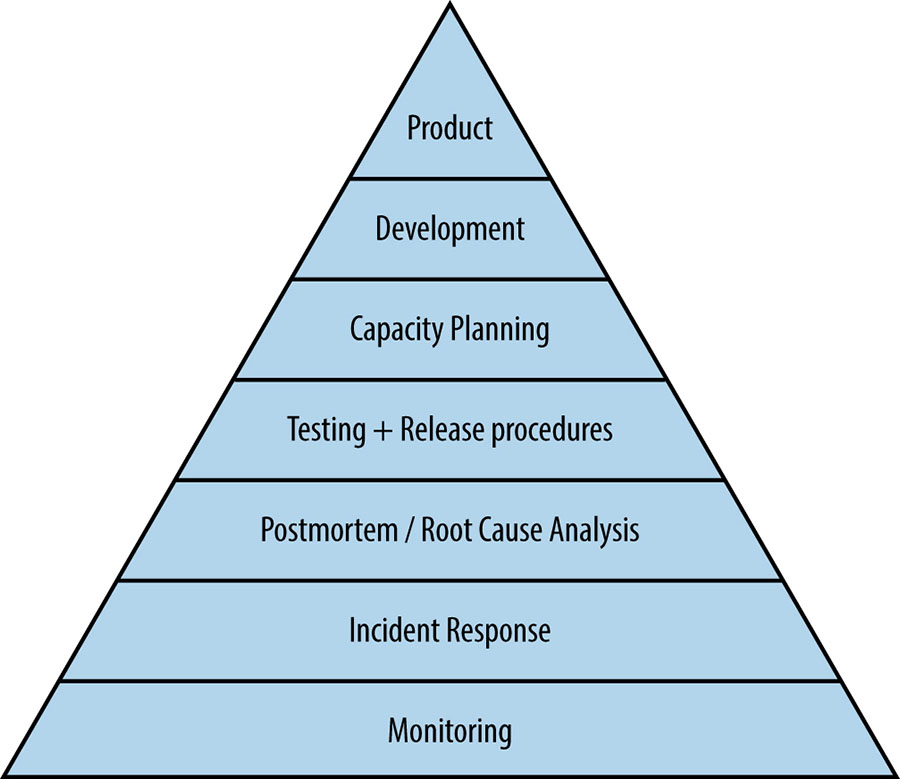
That’s why I call it the SRE pyramid. The ‘hierarchy’ term is used because it plays on Maslow’s hierarchy of needs, also visualized as a pyramid.
This article will analyze the different layers in the pyramid.
I have visually remixed the pyramid into a pathway map with the hope that it’s easier to unpack and explain each layer’s properties. Here’s a quick peek at the visual remix:
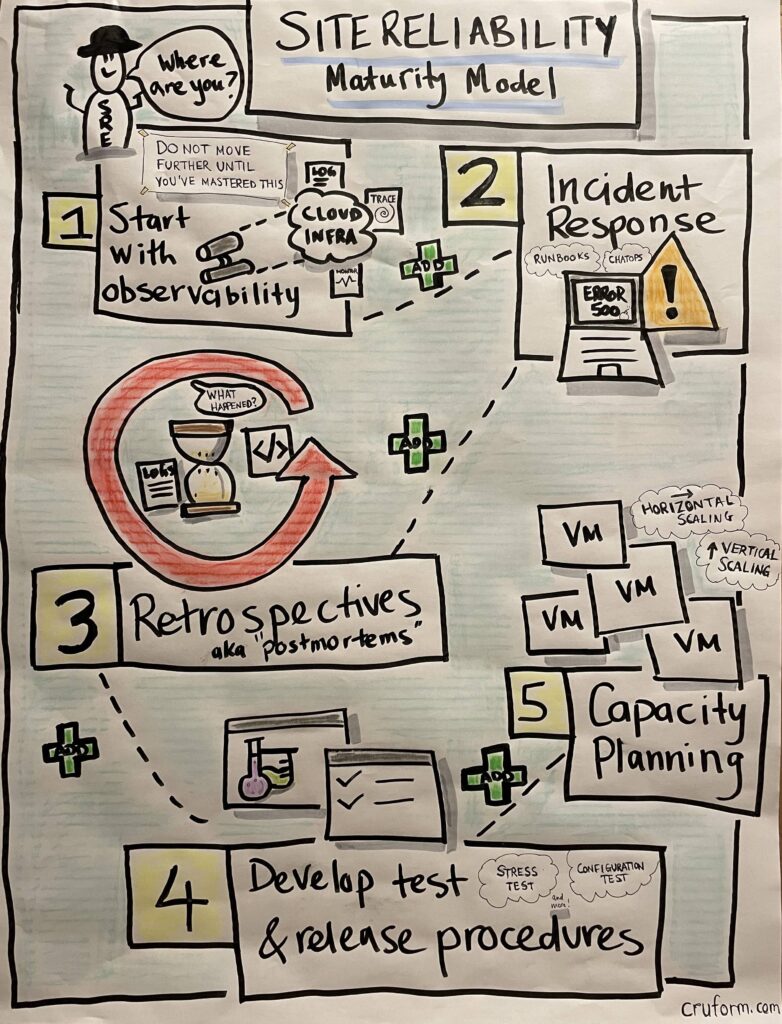
Before I analyze further, let’s cover background information on the SRE book’s hierarchy design choice…
An explainer of the “hierarchy” design
As I mentioned earlier, Maslow’s hierarchy of needs inspires the design of the SRE hierarchy. I will assume you have no knowledge of the former. Let’s see what it looks like:

{kind=link}
You may be able to tell that Maslow’s hierarchy is grounded in behavioral psychology. Let’s explore this hierarchy because it will help us understand Google’s SRE hierarchy better:
- food, water, and shelter are at the bottom of the hierarchy, denoting them as a foundational need
- as you progress up the pyramid, you aim for needs that progressively move further away from mere survival mode
- the highest levels of needs are aspirational and define the character and more advanced levels of being
Maybe now, you can make better sense of the design function of Google’s SRE pyramid hierarchy. But you may not have the luxury of explaining it like this to your peers.
This is where the hierarchy’s design flaw sets in.
Remember that some stakeholders control the budget and organizational capacity of your SRE efforts. People like executive sponsors and upper management.
My experience shows that people like these want a straight answer. “Don’t make me think“.
Many non-technical stakeholders will not admit it, but the pyramid formation will not make much sense to them. I’ve tested this out in real world conversations. People will not be named!
For example, I learned that some senior leaders looked at the hierarchy and interpreted capacity planning as more urgent and important than incident response.
Here’s the SRE hierarchy once again for quick reference:
Seeing that capacity planning was higher in the pyramid than incident response, their interest then prioritized that aspect rather than paying for on-call engineers.
In most situations, incident response is an earlier and more fundamental need in software operations than setting more resources on capacity planning.
See the problem with a misinterpreted “hierarchy”?
The seminal book on change management, Switch by Dan and Chip Heath, highlights how a pyramid shape hierarchy needs to be more clearly defined to make sense.
The problem with the pyramid? Only a [qualified person] could look at it and determine what a person should be [doing] on a day-to-day basis.
from Switch by Chip and Dan Heath
I’ve changed the terminology in the quote from [nutritionist] and [eating] to emphasize the general problem with the pyramid, of which the book goes into deep detail.
What’s Chip and Dan’s suggestion for a more impactful way to drive change and action?
A clear visual picture.
In a Forbes interview, the interviewer noted a key message that Chip Heath repeated several times:
Throughout our interview, Chip used the word “picture” nearly a dozen times. And I realized how easy it is to visualize a group of doctors talking, rather than just writing in a medical chart.
‘Decisive’ Author Chip Heath On Doctors, Diets And The Dangers Of Overconfidence by Robert Pearl MD
It’s also my own trial and error experience as a seasoned operations director that clearly visualized models have more impact in driving new initiatives.
A pathway visual is the simplest and most engaging method to describe the necessary capabilities. Like this one that I drew up earlier this year:
Looks like a maturity model right?
This way lends itself well for starting engaging multi-stakeholder conversations about SRE. A clearer conversation is more likely to form than through a straight-up technical conversation.
The same technical speak that is like catnip for engineers and engineering managers may bore or confuse less technical stakeholders and leaders. I write from experience.
But be warned about pitfalls in following the maturity model path rigidly.
First of all, SRE is a continually moving set of capabilities, not a finish line.
You risk backlash from more experienced Site Reliability Engineers (SREs) if you follow the above path like a prescription.
That’s the exact response response I got when I posted this visual on a popular discussion forum for Site Reliability Engineers.
Most feedback was overwhelmingly positive but there were some countering comments. These comments highlighted criticisms that I want to address here.
Critical feedback: “It’s a good theoretical model in a vacuum, but on-the-job experience has shown me that you don’t always get to handle these in that order.”
Response: I wouldn’t expect to dictate that the model be deployed in the order I’ve outlined it. Every model is good in theory until it hits the real world of competing interests, capabilities, and ambitions.
This simplified model of Google’s SRE hierarchy serves two purposes: (1) as a conversation starter and (2) implying that capabilities should be addressed progressively by new teams rather than all at once.
Critical feedback: “SRE is not a linear process, but a feedback loop where each of these areas (primarily 1-4) are improved incrementally with continuous effort. The notion that you shouldn’t automate “test & release process” until you’ve “mastered observability” is absurd.”
Response: I agree that SRE is not a linear process. This is one of many lenses through which I see SRE, and I want to offer people the choice to take on.
My personal experience has proven a pathway approach to make the whole implementation an easier pill to swallow in complex organizations.
A few things to consider regarding observability vs test and release from an organization design perspective:
- Sure, if you have a strong case for test and release procedures first, why not? But most leaders I have personal experience working with would cave in on their engineers without the prerequisite of having guiding data (that observability offers)
- Another way to see it: observability is a technical exercise with upper management not knowing or caring how you do it… when you start talking about setting policy or procedures, that becomes a sociotechnical exercise involving input from developers, team leads, managers, and ultimately egos and ambitions – with raw data from observability, you can argue for a better path
I will explore my visual pathway map in a future post. For now, enjoy greater clarity around Google’s SRE hierarchy.

- #34 From Cloud to Concrete: Should You Return to On-Prem? – March 26, 2024
- #33 Inside Google’s Data Center Design – March 19, 2024
- #32 Clarifying Platform Engineering’s Role (with Ajay Chankramath) – March 14, 2024