Episode 21 [SREpath Podcast]
Show notes
Sebastian is back for this episode to help set out direction for 2024.
We reflected during the holidays on the problems SREs faced in 2023 in terms of job insecurity, burnout, and “that really shouldn’t be my sole job”.
Sebastian and I talked about what we hope to bring to the community in 2024 to make SREs and SRE teams stronger, happier, and healthier at their work.
My reflections from this episode
In 2024, we need to end this madness. SREs are not purely incident responders.
But I have had far too many conversations that have given me evidence to the contrary. Far more than I could stomach.
I’m a curious sort, so I enquire how SREs do their work when I meet one.
Many have told me point blank that a majority of their time is spent on-call.
They get precious few hours to work on anything remotely proactive.
I consider this to be one of the – if not the – worst antipatterns in Site Reliability Engineering.
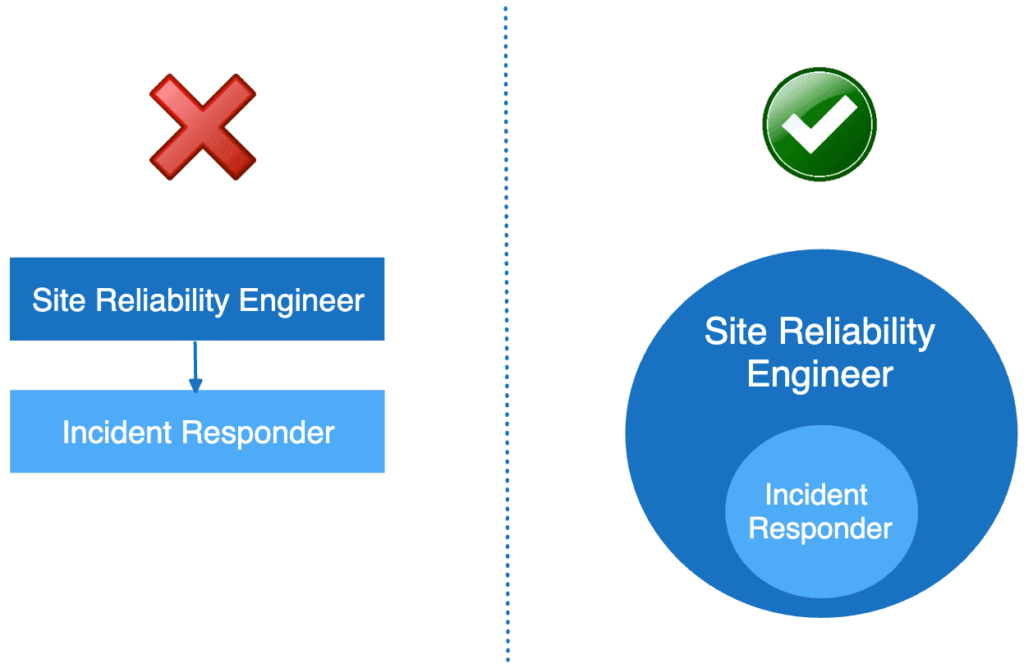
It’s like some managers read the chapter about incident response in the 2016 SRE book and forgot about everything else.
People! There are 100s more pages on what else SREs need to do.
Things alluding to proactive work, working across the software system… you know, enabling team stuff.
Because SREs are enabling teams in the Team Topologies model.
“But wait, Ash, what if we simply need to do on-call because there are so many incidents?”
My friend, that’s a case for concern right there.
This tells me that too little is being done in terms of release engineering, capacity planning and early warning systems like pre-production observability.
And that’s just the tip of the iceberg.
I could rattle off at least 5-6 proactive things you could be doing to reduce future incident severity.
There is something that needs to be said to achieve even a sliver of the above processes.
I align with the viewpoint of industry experts who assert that for SREs to excel, they need:
➡️ Direct access to business stakeholders
➡️ Direct access to developers and infrastructure experts
and in some cases…
➡️ Direct access to users and customers
There is another aspect to the issue and it puts the burden of guilt on people like me.
I feel like I often overwhelm people at SRE conferences about the sociotechnical aspects of the work.
You’d think I would remember they are not part of our little echo chamber where everything SRE is “obvious”.
SRE is far from an obvious practice — incident response antipattern case-in-point.
So the honest truth is, it’s not obvious and we need to work harder.
Harder in what sense?
To make the easier, more productive path to SRE more visible to you and your boss and whoever else needs to know.
That’s my goal for 2024 alongside Sebastian, who will join me from time to time to share ways we can do this.
My first port of call will be to make a section on Observability, covering how to resolve critical problems in that area.
There are many other resources out there already, but I hope to share ideas in as simple a way as I can.
Oh, and for now…
Since you’ve read this far, here’s a plug for the SREpath podcast [Spotify link] that you need to take advantage of.
In Episode #21, Sebastian and I spoke about this incident responder antipattern [Spotify link], which is also the first episode of 2024!
Whether you join us on this fervent journey or pave your own path, we’ll keep working to move SRE to its true North Star.
And let’s hope that is NOT to be a fulltime incident responder.

- #34 From Cloud to Concrete: Should You Return to On-Prem? – March 26, 2024
- #33 Inside Google’s Data Center Design – March 19, 2024
- #32 Clarifying Platform Engineering’s Role (with Ajay Chankramath) – March 14, 2024