The visual summary below is based on a post by Will Larson, who started the SRE function at Uber. His post elaborates on a “trunks and branches” model for developing infrastructure-facing teams.
It also covered an interesting perspective on the balancing act of budget and service quality. I will explain the visual summary underneath it.
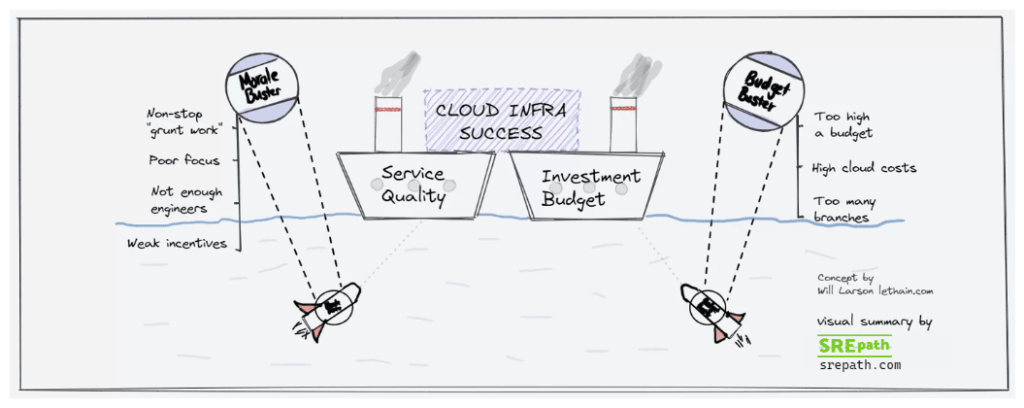
An explanation of the above visual summary
- Long-term cloud infrastructure success depends on balancing both elements of high Service Quality and a reasonable Investment Budget
- Service Quality can get torpedoed by morale busters like non-stop grunt work, not enough engineers, etc.
- Investment budget can get torpedoed by continuously high cloud costs and an excess of branch teams working on problems that aren’t solving immediate problems
- The key is to always keep an eye on these “busters” that can torpedo your long-term return on cloud investment

Reliability Nut at SREpath
Ash has an unhealthy obsession with software reliability. Maybe it’s got to do with the trauma of working at a few companies where software kept slowing or went down while he worked to turn it around. His ma hopes that he can one day turn this passion into a respectable job or business. Still waiting…
Latest posts by Ash Patel (see all)
- #34 From Cloud to Concrete: Should You Return to On-Prem? – March 26, 2024
- #33 Inside Google’s Data Center Design – March 19, 2024
- #32 Clarifying Platform Engineering’s Role (with Ajay Chankramath) – March 14, 2024