I recently read a post by Will Larson, who started SRE at Uber. The post is called the Trunks and branches model for scaling infrastructure organizations.
Several passages in the post covered how infrastructure teams can evolve from the startup phase. I felt it would be easier to comprehend the dense-and-rich advice with a visual summary.
Check out what I put together below.
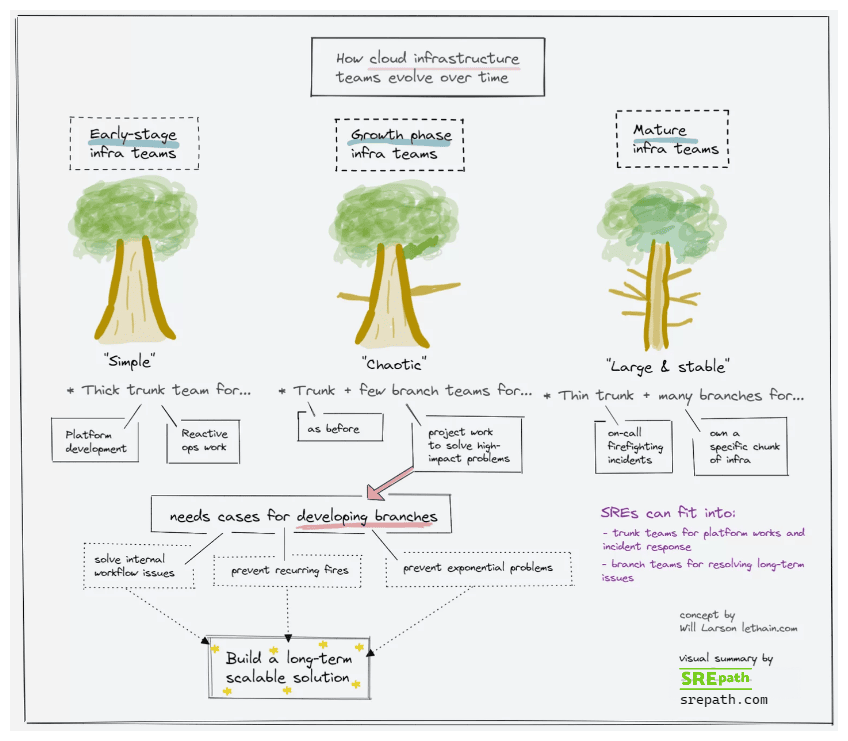
Explanation of the visual summary of cloud infrastructure teams
The key premise of Will Larson’s trunks and branches model is that infrastructure teams evolve from starting up i.e. early-stage to a usually chaotic growth phase and finally to mature & stable.
Let’s start from the very beginning.
Early-stage cloud infrastructure teams
The typical cloud infrastructure initiative starts with one team that handles almost everything. Rarely does a full-blown investment into multiple teams occur from the outset.
The work at this early stage is mostly generalist in nature. It may include platform work like provisioning virtual machines on AWS, Azure, GCP, or other cloud providers.
It may also include reactive work like an incident response when outages occur.
Growth phase cloud infrastructure teams
Prickly problems will start to emerge across the entire infrastructure footprint as the cloud service serves more users or hosts more resource-intensive applications.
The original team handling the overall system might not have the mental bandwidth or requisite skills to resolve these emerging issues. It’s sometimes the case that early trunk teams are proficient at handling only the core AWS or GCP, or Azure services.
Let’s use AWS as an example. A trunk team might know how to run core services like EC2 instances with S3 storage and VPC. This team may be known in some organizations as the platform team.
Anything beyond that will pose a challenge or even be impossible for them.
As software services evolve in complexity, their data may need to be stored in distributed databases. Distributed databases comprise a complex software architecture.
In addition, AWS alone has a suite of 200+ services to serve specific use cases, most of which would be beyond the scope of a generalist trunk team.
During this chaotic growth phase, managers responsible for cloud infrastructure may add branch teams to the main trunk.
The aim would be to have branch teams solve specialized problems like implementing more cloud services, supporting trickier architectures, unclogging internal workflows, and handling recurring outages.
Site Reliability Engineers are well-placed to support engineers doing this kind of work. After all, effectiveness in this area will likely translate to better software performance and reliability.
Branch teams may specifically own a sliver of the entire cloud architecture e.g. storage, compute, chaos, and performance management.
Stable and mature infrastructure teams
The final mature stage is arguably the goal for organizations managing cloud deployments. Its stable nature implies a degree of predictability and stress mitigation.
At this point, the cloud infrastructure serves a complex software system with 100s to 1000s of services.
There will be many branch teams to handle specialized and long-range issues. They possess specialized knowledge to identify which of today’s minor problems will become tomorrow’s big problems.
Site Reliability Engineers are well-placed to work at this phase because they are specialists in handling complex software systems across several branches.
A mature cloud infrastructure organization will have the thinnest possible trunk of non-specialist infrastructure engineers. There may be occasions where branch team engineers rotate in-and-out-of trunk teams on temporary assignments.
Keep in mind that their level of ability means that branch teams don’t routinely participate in the “trunk team” type of work of service provisioning or out-of-hours incident response.
Branch team members out on rotation can use this opportunity to identify issues that can be resolved with their specialist expertise.
Conclusion
I hope the visual summary and its explanation have given you clarity on how cloud infrastructure teams can evolve from startup to maturity.

- #34 From Cloud to Concrete: Should You Return to On-Prem? – March 26, 2024
- #33 Inside Google’s Data Center Design – March 19, 2024
- #32 Clarifying Platform Engineering’s Role (with Ajay Chankramath) – March 14, 2024