This article aims to help engineering leaders consider issues before starting a software reliability team. Since I am an advocate for Site Reliability Engineering (SRE), we will now refer to such a team as the “SRE team”.
Besides creating a new team, leaders face many responsibilities that are often invisible to individual contributors and their reporting managers.
Part of a software reliability leader’s responsibilities include:
- Managing up, down and across various stakeholders like developers, direct reports, other engineering leaders, senior leadership, and more
- Defining the tools, processes, and systems needed for day-to-day work
- Building and organizing several types of teams
None of the above work is ever straightforward. You’re working against continually moving targets that require ongoing assessment and readjustment.
It’s better to be well prepared because the need for a reliability team may come suddenly.
Software reliability may be a non-priority one day for an organization and a mission-critical need the day after.
This recount by Wayne Bridgman on the origin story of BT (British Telecom)’s SRE team describes how the need for reliability can fall into your lap: “I was sitting at my desk when our digital engineering director came over and asked a seemingly casual question, ‘Have you ever heard of SRE?’”.
That conversation snowballed into a flurry of meetings, which led to senior leadership saying BT must get into all things reliability through a new SRE team.
Starting and funding an SRE team first involves uncovering the burning platform in the organization.
“But wait, what is a burning platform?” Very briefly, a burning platform implies that the problem is both urgent and bad enough to cause a strategic change effort.
Magic can happen when this burning platform becomes apparent. Senior leadership gets actively involved, funding appears out of nowhere, and more. A more thorough explanation of the phrase “burning platform” can be found here.
Burning platform issues that support forming a software reliability team
Business issues
Technical issues
💡 Advice – there is a solid case for a dedicated SRE team if you ticked at least one box in the Business issues section plus 1 or more in Technical issues
Download the above checklist as a PDF:
What options do you have before forming a software reliability team?
Let’s go down a gear for a moment. Not every organization can or wants to begin its software reliability journey with a dedicated SRE team.
Many organizations experiment with various commitment levels of reliability work before they commit to hiring and managing a full-fledged SRE team.
This often stems from the fact that there are many obstacles to starting a function focused on software reliability. In the beginning, you may face the following:
- no headcount
- no spare resources
- no budget
However, certain trigger events can prompt an organization’s journey toward a dedicated software reliability function.
Actions that may accelerate the need for reliability as a function may include:
- dealing with outages on an ad-hoc basis with no method or process for approaching incidents (then finding that services are at high risk of failing to meet customer and partner SLAs)
- making developers responsible for platform, observability, and incident response on developers for their respective services (but then finding that they are spending too much time on this)
The above are problematic steps that lead to a natural progression toward a fully-fledged SRE team.
I’ve outlined these steps in the image below:
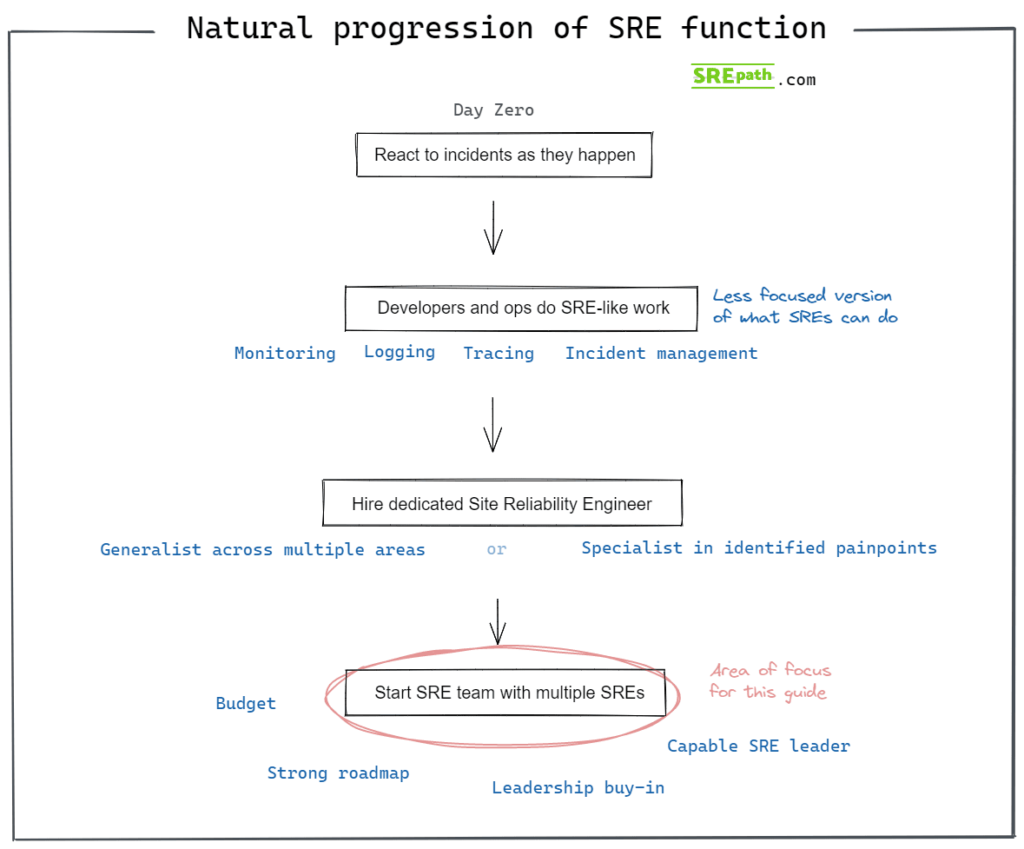
Critical factors before starting a successful software reliability function
Solid budget
With an average salary expectation of $130,000+ in the US, you need a sizeable budget to hire several reasonably experienced Site Reliability Engineers.
The salary expectation is usually lower in other countries including Western Europe, but due to the rarity of the role and scope of work, is still likely to exceed what you’d pay a developer.
Strong roadmap
The pay-and-pray approach may be viable for running a team in a well-defined field of work, but SRE is anything but. The work is ambiguous, volatile, and complex.
So it’s important to have a roadmap of what you expect to achieve in 0, 3, 6, and 12 months – even if it’s just for driving individual contributor morale.
There is a myriad of opportunities in SRE. Where to start? Observability? Tooling? Platform enhancements? DevSecOps? Managing toil? The key is to work on capabilities that can add value quickly.
Here’s an amalgam of tips for doing this:
- Do things first that enhance the ability to run services cost-effectively.
- Work on automation to minimize manual work that compounds over time.
- Focus on observability if you don’t already have a strong apparatus. It will help you to focus your attention in a complex software environment.
As your software reliability team and function matures, you can look at more ambitious organization-wide goals like:
- Implement guardrails allowing for fast but reliable rollouts
- Disseminate best practices to developers
- Drive deeper automation of workflows
- Identify and focus on problem zones in services
Leadership buy-in
This ties in reasonably well with having a solid budget. Without senior leadership approving the function, you’re not going to have a sizeable enough budget.
The other issue to consider is that SRE teams need senior leadership to give them access to other parts of the organization where they work to make an impact.
An example would involve teaching DevOps principles to developers. Without a senior leader’s blessing, SREs may not be able to get across to the developer teams and their leaders.
One thing to do for sure: manage senior leadership expectations. Many are confident and ambitious people, so they may possess a degree of survivorship bias of a straight line to success.
Make them aware that the path forward will not be a straight up-and-right arrow. It will be a series of wins and setbacks that will give a very squiggly line to success.

Capable SRE leader
A Site Reliability Engineering leader at the ground level is a critical component of the team’s success. This may be taken as a technical and people leadership role in one.
In the early days, a dedicated technical SRE leader may not be available. So as a capable leader, you may need to step in and set both the technical and people direction.
You may play the role of SRE advocate, to share knowledge and provide credibility to the cause by having a clear direction for the function from Day 1.
You may wish to read up on leadership advice from engineering leaders like Camille Fournier (JP Morgan) and Heidi Helfand (Kin Insurance).
You may also wish to read up on technical leadership advice from reliability leaders like Will Larson (ex-Uber) and SRE experts like Niall Murphy (Azure).
I’ve outlined a few questions below that aim to challenge your thinking as a capable reliability-focused leader.
5 questions to ponder before starting to advocate reliability as a leader:
- Will we hire Site Reliability Engineers from an external talent pool, retrain internal candidates (like developers and SysAdmins), or both?
- How do we define what success will look like for a Site Reliability Engineer, for immediate impact, and in the foreseeable future?
- What capabilities does our system call for besides the core requirements of observability, incident response, etc.?
- How do we allocate responsibilities to each Site Reliability Engineer to ensure all aspects of our required capabilities are covered?
- How do we continue to do all of the above as the reliability function evolves?
Recruiting people into the SRE steam appears to be a major sticking point for many leaders and organizations. Why not draw from areas beyond the usual search pools of “already an SRE”, SysAdmin or developer pool?
Considering pulling people from various areas to learn from each other, but most importantly teach each other. Example areas include L2 support, FinOps, environments and technology governance.
Now that you’ve reviewed the fundamental questions, I’ll share some parting tips with you:
- Allow for the development of subject matter experts in key areas
- Don’t have a single-point-of-failure (SPoF) of one person who hoards all knowledge and access in one area
- Have a regular cadence for reviewing high-level issues: architecture and service topology, development environments, and deployments
- Double down on cultivating the mindset & culture because without it, people will start thinking SRE is a project with a start and stop
- Never underestimate how much you need to do to create a shared responsibility model for on-call and observability instrumentation
- Set aside time blocks for non-technical meetings like leadership coaching, retrospectives, and values-reinforcing sessions
- Invest in the ongoing development of your individual contributors’ abilities including capabilities you don’t cover yet
- Make accessible playbooks for known issues and processes so that people don’t reinvent the wheel when doing routine work
Examples of automatable or playbook-able processes:
- Open support incident
- Scale services up or down
- Run end-to-end tests
- Collect logs/extend context
- Rollback to a stable state

- #34 From Cloud to Concrete: Should You Return to On-Prem? – March 26, 2024
- #33 Inside Google’s Data Center Design – March 19, 2024
- #32 Clarifying Platform Engineering’s Role (with Ajay Chankramath) – March 14, 2024